
Building Smarter White-Label Apps with Modular SDKs
Leandro Pontes Berleze | Mar 12, 2026

In this blog post you’ll discover what is fuzz testing, also known as fuzzing, and all types of fuzz testing that exist with examples.
Furthermore, you’ll understand the benefits of using fuzz test and also check out some projects in which it was used in Cheesecake Labs.

Fuzz testing is an automated testing method in which we provide random input values to discover unexpected bugs.
Fuzzing can be traced back to the University of Wisconsin in 1988. There, Professor Barton Miller gave a class project titled “Operating System Utility Program Reliability – The Fuzz Generator.”
It was the first – and simplest – form of fuzzing, and included sending a stream of random bits to UNIX programs with the use of a command line fuzzer.
Nowadays, there are some different types of Fuzz Testing: dumb fuzzing, smart fuzzing, feedback-based fuzzing, mutation-based fuzzing, and generation-based fuzzing, which are all described below.
There are two Fuzzing styles of generating randomized data:
Dumb fuzzing requires less amount of work, it’s easier to maintain, but it has limited coverage.
It is relatively easy to set up, but it is also very inefficient because it is not based on any criteria, it just generates the entirely random data.
Otherwise, Smart fuzzing has a greater code coverage, catching more bugs. Smart Fuzzing Test produces inputs that are based on valid input formats.
It is very useful since we need to match certain patterns. This style of fuzzing requires detailed knowledge about input format, so it is more costly to set up, which involves a longer development and bigger strategy.
Depending on the environment, we can use both types in the code (Smart and Dumb Fuzzing).
Smart is selected for parts where we need more strategy and match specific criteria. Dumb is for the simplest tests, where we just need to randomize without any criteria.
Smart randomizing style can be divided into three types:
Sometimes we can find different names or explanations for each fuzzing style/type.
Here is a description of each one for a better understanding.
It changes the valid inputs generating a collection of mutated inputs, which then introduces small changes to existing inputs that may still keep the input valid with new behavior.
Sometimes it’s classified as “dumb-fuzzer” considering the mutation of the whole input data.

It creates entirely new data matching the valid input, according to the defined structure. It can be defined by data modeling or a state modeling, for example.
The Model is defined and the fuzzer randomizes the data according to the model structure.
Here is a sample Data Model for HTTP Protocol:

Here is a sample State Model and Data for HTTP:

Also called “Coverage-based”. It uses code coverage information when generating new inputs.
It is considered the smartest way of Fuzzing, but also the most costly one. This type measures the amount/share of code executed during a given test.
For example, it may read the number of statements in the code and compare it to the statements in the software source.
Same thing for the number of lines, the share of defined functions that have been called, the execution of code lines within basic blocks, the edges of the control graph that are being followed, the number of logical paths, etc.
Fuzzing Tests can be highly configurable. Some important configurations we had to use in our projects are listed below.
Considering we worked with blockchain, it was very important to determine a limit of time for a specific test. This way, we could also test performance and determine a time limit so we would not be sending infinite data.
We could configure Fuzzing to be working in several parallel processes. It also got useful for performance testing and we could test the behavior on the network receiving several parallel data at the same time.
The Fuzzing can be configured to accept only specific types of data. Very useful for an environment where we need to randomize, but aiming only one or more specific types of data.
Considering we need to pay special attention to security on blockchain projects, and need to test the widest range of accepted data possible, fuzzing tests are very interesting for the blockchain environment.
Fuzzing is very important to test security because it may test what kind of data the system is accepting or not accepting, and also test simultaneous parallel processes certifying one process is not overlapping another concurrent process using random inputs.
It’s important to certify the system is working according to the real environment of a blockchain network, receiving several different data simultaneously, and being accepted by the network rules without losing important information.
When facing specific scenarios, such as creating different varieties of crypto wallets and transferring values between them, it was necessary to test a large amount of random and valid inputs, simulating simultaneous transactions such as in a blockchain network.
A good code coverage was required for unit tests but in a randomized way. This helped us identify a lot of bugs we couldn’t find with approaches other than Fuzzing.
There were many unexpected inputs that generated errors and other issues that emerged when simulating heavy usage.
We had difficulty implementing the Fuzzing Test using a specific programming language because each language has its own patterns for the Fuzzing Test.
For example, we coded using Go Language, which had Fuzzing structure available only in version 1.8.
Depending on the project’s programming language, we would have to implement Fuzzing with another language that has a structure for it.
Another difficulty was performance. We used smart fuzzing, but couldn’t immediately find where the code was breaking.
Because of that, we had to study the Fuzzing structure for the specific programming language in our project environment, which changed the form of implementation.
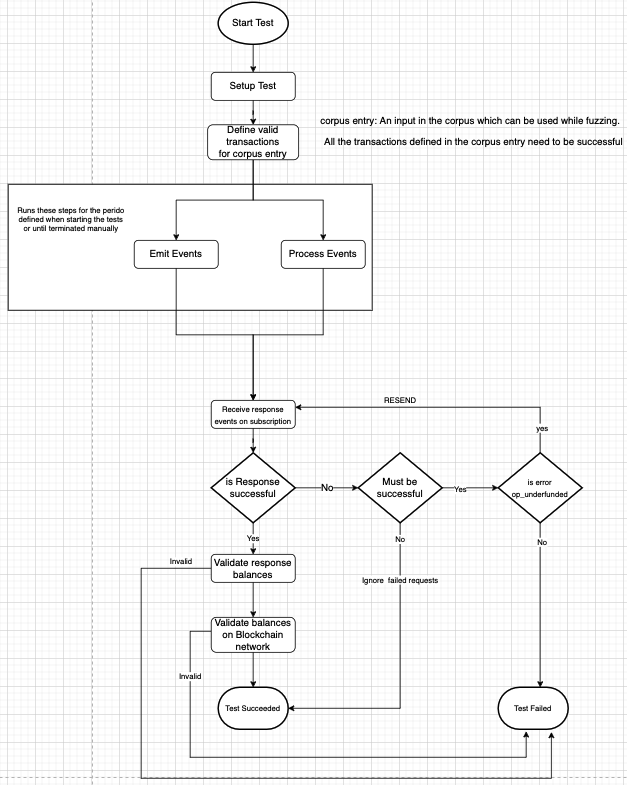
In a blockchain project, while sending parallel fuzzing events, sometimes we had problems with events that couldn’t be sent in a specific sequence, so we had to find a way to verify the event condition (see example in the diagram below).
When running parallel fuzzing to send multiple random transactions, we found out that some transactions were being generated without the proper sequencing management, which would cause transactions to fail during peak activity.
Once this scenario was identified, it was possible to improve the solution by applying a different submission strategy and scaling it up to handle a high volume of transactions with consistency.
Fuzzing allowed us to identify and work around some edge cases like the inability to handle some non-ASCII characters and other similar unforeseen scenarios.
Here is a project diagram example with Fuzzing Test applied in blockchain:
func FuzzTestHTTPHandler(f *testing.F) {
// Create a new server hosting our calculate func
srv := httptest.NewServer(http.HandlerFunc(CalculateHighest))
defer srv.Close()
// Create example values for the fuzzer
testCases := []ValuesRequest{
ValuesRequest{[]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}},
ValuesRequest{[]int{10, 9, 8, 7, 6, 5, 4, 3, 2, 1}},
ValuesRequest{[]int{-50, -9, -8, -7, -6, -5, -4, -3, -2, -1}},
ValuesRequest{[]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20}},
ValuesRequest{[]int{10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200}},
}
// Add Corpus Seeds
for _, testCase := range testCases {
// Skip error, very bad practice
data, _ := json.Marshal(testCase)
// Add JSON data as Corpus
f.Add(data)
}
// Start fuzzing
f.Fuzz(func(t *testing.T, data []byte) {
// Validate that it is proper JSON before sending
if !json.Valid(data) {
t.Skip("invalid JSON")
}
// Make sure it is a real ValuesRequest formatted payload by marshalling into
vr := ValuesRequest{}
err := json.Unmarshal(data, &vr)
if err != nil {
t.Skip("Only correct requests are intresting")
}
// Create a new request
// using DefaultClient, should not be done in prod
resp, err := http.DefaultClient.Post(srv.URL, "application/json", bytes.NewBuffer(data))
if err != nil {
t.Errorf("Error: %v", err)
}
// Check status Code
if resp.StatusCode != http.StatusOK {
t.Errorf("Expected status code %d, got %d", http.StatusOK, resp.StatusCode)
}
// Umarshal data
var response int
err = json.NewDecoder(resp.Body).Decode(&response)
if err != nil {
t.Errorf("Error: %v", err)
}
})
}
Code font: towardsdatascience.com/fuzzing-tests-in-go



