What We Learned Exploring AI Prototyping Tools
Stephanie Baptista | Mar 17, 2026

Most AI product teams spend months debating which model to use. The teams that actually ship reliable products at scale are thinking about a different question entirely: what happens when that model fails, costs too much, or responds too slowly, and how does that reality shape the way the product is priced?
Model fallback and AI pricing strategy are not engineering details. They are product decisions with direct consequences for user trust, retention, and revenue sustainability. Getting them wrong does not just create technical debt; it creates business risk.
This article walks through a five-layer framework derived from real production experience building AI-powered products, covering how intelligent routing, fallback architecture, financial observability, value-based pricing, and guardrails work together as a coherent product and engineering strategy.
Building an AI product and looking for experienced partners? Explore Cheesecake Labs’ AI development services
The gap between a working AI prototype and a reliable production product is wider than most teams expect. Industry data makes this visible: roughly 40% of LLM outputs, according to OptimusAI, are not consistently reliable in production environments, and around 95% of AI pilots, according to Typedef.ai’s study “13 LLM Adoption Statistics”, stall before reaching scale — not because the models underperform, but because the surrounding infrastructure is not designed to sustain real usage conditions.
The root cause is almost always structural. Teams build features that work in isolation but lack the operational layers needed to handle cost variability, model failures, and unpredictable user behavior at scale. When those layers are absent, AI products become expensive to operate, fragile under load, and impossible to price sustainably.
The solution is not a better model. It is a better architecture — one that treats model fallback and pricing as first-class product concerns from day one.
The framework below reflects how production AI systems need to be structured when reliability, cost control, and user trust are non-negotiable requirements. Each layer addresses a specific failure mode that appears consistently across AI product development.
“We don’t sell tokens. We sell reliable solutions. The architecture must reflect that.”
The single most impactful architectural decision in an AI product is also the most commonly overlooked: not every task requires the same model.
In practice, cost differences between the cheapest and most expensive commercially available models can reach 20x or more. Using Claude Sonnet 4.5 at $3.00 per million input tokens for every request — including simple summaries, data extractions, and short classifications — when a model at $0.15 per million tokens handles those tasks equally well is not a quality decision. It is a marginal decision made by default, and it is unsustainable.
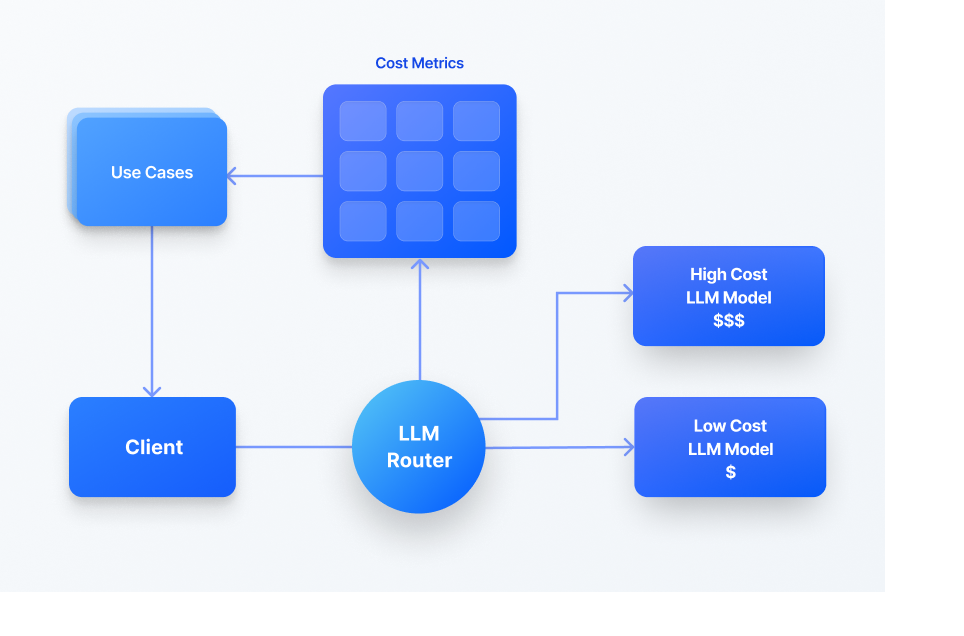
A well-designed routing layer dynamically assigns each task to the most appropriate model based on complexity, balancing three variables simultaneously: cost, latency, and output quality.
Latency compounds the cost argument. Higher-capability models are slower — not marginally, but meaningfully. A user waiting 30+ seconds for a response to a simple request will not stay. They will reload the page, assume the product is broken, and lose confidence. Routing decisions affect both the income statement and the product experience.
At 20x cost variation, intelligent routing is not an optimization. It is a product survival decision.
Rate limits, server errors, and infrastructure outages are not edge cases. They are operational facts for any AI product running in production. The architecture question is not whether failures will happen — it is whether the product recovers automatically and transparently, or exposes failures directly to users.
Most developers design fallbacks like a ladder: if Model A fails, try a slightly better Model A. In a true production environment, this can lead to outages.
A production-grade fallback architecture is not a linear list; it is a matrix. You must solve for two different types of failure simultaneously: loss of service and loss of quality.
When a model returns an HTTP 429 (rate limit) or a 5xx server error, the system triggers a Circuit Break pattern. The failing model enters a quarantine window, starting at 10 minutes and utilizing Exponential Backoff in production-grade systems, during which the system automatically routes requests to the next model in the sequence. After the cooldown period, the original model is retested automatically, since many failures are transient.
Critical distinction: not every error type warrants a fallback. When input exceeds a model’s context window, routing to a smaller model will produce the same failure — smaller models have narrower context limits, not wider ones. In these cases, the correct response is a clear user-facing message with a meaningful next step, such as opening a new conversation.
Multi-provider architecture adds a qualitatively different layer of resilience. By distributing across two independent infrastructure providers (for example, AWS Bedrock as primary and Groq as fallback), the system eliminates its single point of failure. If one provider goes down entirely, traffic shifts automatically without any user interruption.
The principle that guides this entire layer: the “magic” of an AI product is not that the model is always perfect — it is that the product never stops working.
From a product perspective, fallback is also a pricing conversation. When model pricing changes without notice — which LLM providers do regularly — teams without fallback architecture face a binary choice: absorb the cost increase or break the product. Teams with a tested fallback chain can absorb that disruption in minutes.
One of the most consequential gaps in early-stage AI products is the absence of cost visibility at the operational level. LLM-based systems have dynamic, per-token pricing across multiple models and providers. Without deliberate tracking, costs accumulate invisibly until an invoice makes the problem undeniable.
Financial observability means tracking cost not just per API call, but per operation type — per feature, per workflow, per interaction. Every distinct product action should have its cost attributed individually: chat messages, task planning, tool selection, automation runs, and report generation.
This granularity transforms how product and business decisions get made.
A real consequence of implementing this: When a team enabled operation-level cost tracking on an automation feature, they discovered the feature was costing $4 to 10 per execution — significantly more than the monthly subscription price they had been planning to charge.
Without that data, they would have launched a feature that actively eroded margins. With it, they redesigned the pricing model, shifting from monthly to weekly billing, to align the user-facing price with the actual delivery cost.
Infrastructure consideration: reporting queries should not compete with production traffic. A practical implementation logs token usage to a primary operational database (for real-time tracking) while syncing to a dedicated analytics replica on write. This ensures reporting never degrades the user experience.
Prompt caching adds a complementary cost reduction lever. For long, static, frequently repeated prompts — such as those describing available tools, system configurations, or data models — caching can reduce token costs by up to 90% by serving stored results rather than re-invoking the model. This is particularly valuable for automation workflows where the same system context is sent repeatedly across different user sessions.
Financial observability is not just cost control infrastructure. It is the data layer that makes a pricing strategy possible.
How an AI product prices externally should reflect how it is structured internally. And the most common structural mistake is pricing based on token consumption.
Token-based pricing has a predictable failure mode: it transfers the complexity and unpredictability of model economics directly to the user. Non-technical audiences — which is most end users — cannot evaluate whether a 2,000-token response represents good value. They do not know what a token is, and they should not need to. Exposing that complexity creates friction, reduces adoption, and misaligns perceived value with actual product utility.
Value-based pricing replaces token consumption with task completion as the billing unit. Users pay for what they receive: outcomes, reports, automations, and summaries.
For a task with 2,000 input tokens and 500 output tokens:
An automation that runs once per business day, using a premium model, costs approximately $5-10 per execution; $100-200 per month at full usage. That unit economics reality should drive how the feature is packaged and priced before launch, not after users start complaining about unexpected charges.
The core principle: the price of a feature should reflect the value it delivers — the task resolved, not the cost of the infrastructure that processed it.
Guardrails are the layer that makes AI products safe to use in production — for users, for the business, and for compliance purposes. They operate in two directions simultaneously.
Input guardrails intercept problematic requests before they reach the model. This includes filtering out PII that should not be sent to external LLM providers, blocking queries outside the product’s defined scope (avoiding unnecessary token spend on out-of-scope requests), and enforcing rate limits at the user and organization level to prevent margin erosion from power users.
Output guardrails validate what the model returns. This means checking for policy violations, inappropriate content, data that should not be surfaced, and brand consistency failures. A guardrail that catches a competitor’s name appearing in a brand’s customer-facing chatbot response is not a minor technical feature — it is reputation protection.
A second model call can serve as an automated self-check: a separate invocation that evaluates response quality and compliance without the context of the original conversation. This LLM-as-a-judge pattern enables scalable quality auditing that would be impossible to do manually at any meaningful volume.
Guardrail telemetry is as important as the guardrails themselves. Teams should track:
The user-facing side of guardrails matters as much as the technical implementation. When a limit is reached, the product should explain what happened and offer a meaningful alternative — not show a generic error. “You’ve reached the context limit for this conversation. Open a new chat to continue” is a product experience. A blank screen or an unexplained error is a trust problem.
Budget guardrails also create the conditions for transparent pricing. When users understand that each interaction costs a defined number of credits, and when limits are communicated clearly before they are reached, the pricing model feels fair rather than arbitrary.
There is a real and unavoidable trade-off in AI model selection that product teams often avoid: higher-quality models are slower, and that slowness is not accidental — it is structural.
When a model enters “thinking mode” — the extended reasoning process that produces higher-quality outputs — it is, by design, taking more time. The quality is inversely proportional to the speed of token generation. Asking a team to find a model that is simultaneously the cheapest, fastest, and highest-quality is asking for something that does not exist today.
This creates a genuine product decision: which tasks justify the latency cost of a premium model, and which tasks are better served by a fast, cheap model that responds in under two seconds?
The answer is rarely “use the premium model for everything.” The answer is intelligent routing, tested and calibrated against real usage data — starting with the best model available, stepping down until quality degrades unacceptably, and locking that configuration in code.
The teams that get this right do not debate model selection philosophically. They instrument their systems, measure outcomes, and let data drive the routing policy.
The same failure modes appear repeatedly across AI product teams, and most of them are architectural decisions made too early or not made at all.
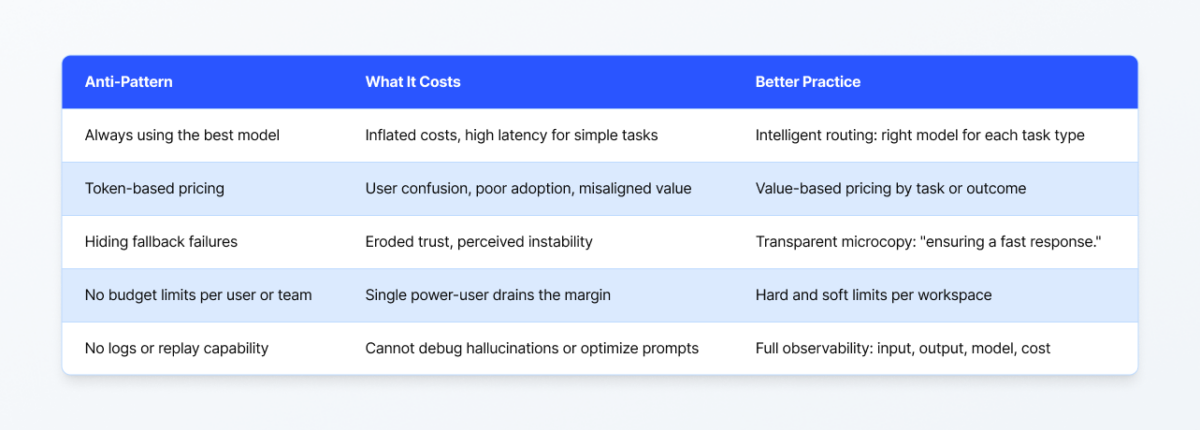
Avoiding these patterns at the architecture phase is dramatically cheaper than refactoring around them after a product is in the hands of paying customers.
Cheesecake Labs partnered with Knapsack to re-architect their AI platform — evolving it from a fully local prototype to a hybrid, compliance-first system ready for enterprise scale.

“We couldn’t have solved some of the complex problems to deliver this product without the support of Cheesecake Labs’ team.”
Mark Heynen — Co-Founder & Chief Product Officer, Knapsack

The gap between an AI prototype and a production-grade AI product comes down to decisions made about model fallback, routing, observability, and pricing—long before most teams even consider them.
At Cheesecake Labs, we help product teams make these decisions right from the start by building AI systems that are resilient, cost-aware, and designed to scale sustainably.




