What 12 Years of Building in Regulated Industries Taught Us About AI That Most Firms Get Wrong
Falcon Stephan | Jun 30, 2026

We all use a lot of web applications, such as Gmail, Evernote, LinkedIn or Telegram as productivity enhancers in our daily lives. However, there are not-so-rare moments that these services go down for a variety of circumstances.
In a recent event, due to Brazil’s Department of Justice decision to block access to WhatsApp in the whole country for 48 hours, millions of Brazilian users suddenly migrated to Telegram, generating a huge (and unexpected) load in their servers. Since this is not the first time this happens, Telegram was well-prepared and handled the usage peak gracefully (even though there was an SMS service bottleneck).
However, in a previous user base sprout, Telegram had a 2-hour outage in some parts of the world, as they said in their official Twitter.
Don’t get me wrong: I think Telegram was totally on top of this. The fact that they could solve this issue in a 2-hour window says they were prepared for cloud scaling – which unfortunately isn’t always true for all web services.
So how can you prepare for scaling? How can you be sure the cloud service you’re creating is prepared to handle a big user base (or a sudden increase in access) without going down?
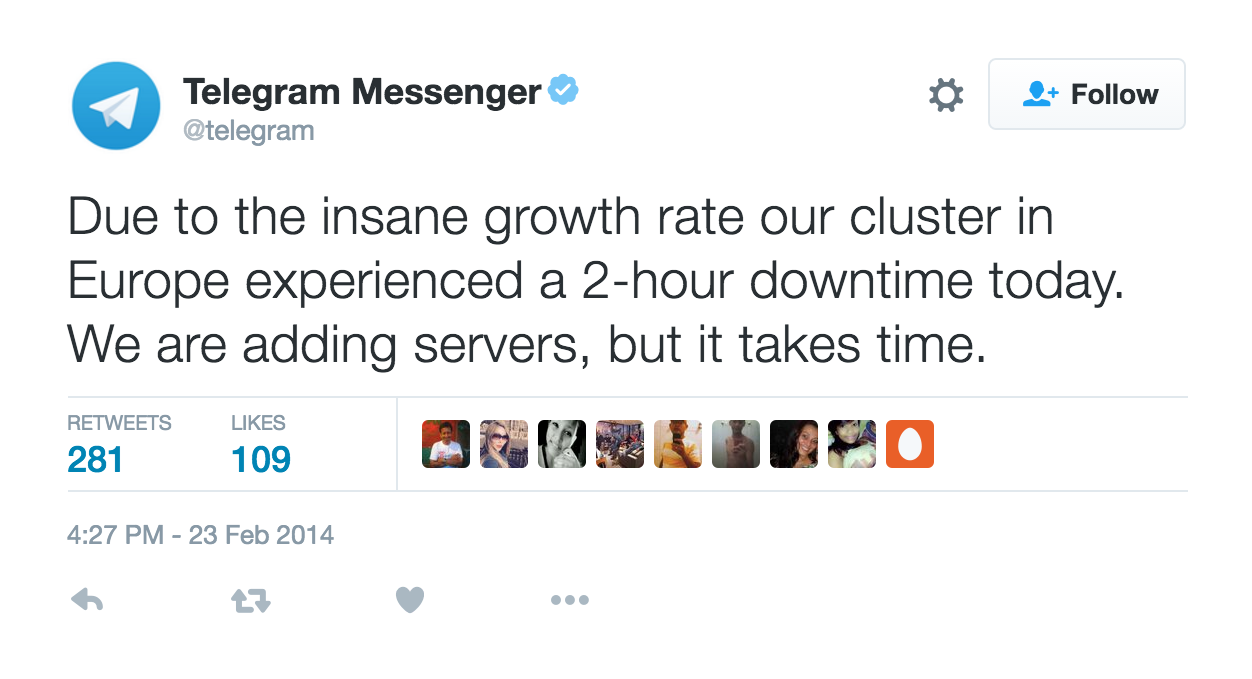
Source: Twitter
Here’s a breakdown of 5 basic tips to ensure your services can scale from 1k to 1b users in a cost-effective manner:
Your Cloud is a set of (physical or virtual) computers. As such, they have a limited capacity of processing data, storing, and distributing it over the Internet – like your own personal computer. Considering that, there is a limit on how many tasks they can accomplish.
When your cloud becomes incapable of handling more tasks due to usage growth, there are two ways to proceed: increasing the capacity of the existing ones (vertical scaling) or adding more machines (horizontal scaling).

Source: https://blog.fi-xifi.eu/wp-content/uploads/2013/11/scalability-vertical.png
Vertical scaling means switching the existing machines to more powerful ones, so they can handle more tasks. This might be a good short-term solution, but you’ll have to rely on hardware updates to scale your product. And the more you reach the bleeding edge of hardware technology, the more expensive the upgrades become, making your expenses grow exponentially.
Horizontal scaling, on the other hand, means adding more less-capable machines and distributing the tasks among them. Although this might sound less cost-effective at first, the prices will grow linearly (rather than exponentially), and you can virtually add as many machines as you want to the processing cluster. What is more, you can easily shut down machines that aren’t necessary anymore, without any migration or downtime.
The great majority of web services that we rely on a daily basis are built on horizontally scalable architectures – and this is what Telegram referred to when it said “We are adding servers” in the Tweet we mentioned above.
There are several Cloud Platforms that enable the dynamic allocation of resources on-demand, like Amazon Web Services, Heroku or DigitalOcean.
So we defined that our cloud should be horizontally scalable, which means we’ll have several machines (nodes) that will be responsible for handling the similar tasks. However, for the structure to be truly elastic – meaning it can upscale and downscale when needed – there should be a gatekeeper who is in control of routing the messages.
This is why we need a load balancer: a machine that knows where all the other machines are, and what kind of tasks they can handle. When you’re accessing a website like google.com or twitter.com, you’re not actually connecting to a single machine: you’re connecting to a load balancer that will redirect your access to the least busy machine:
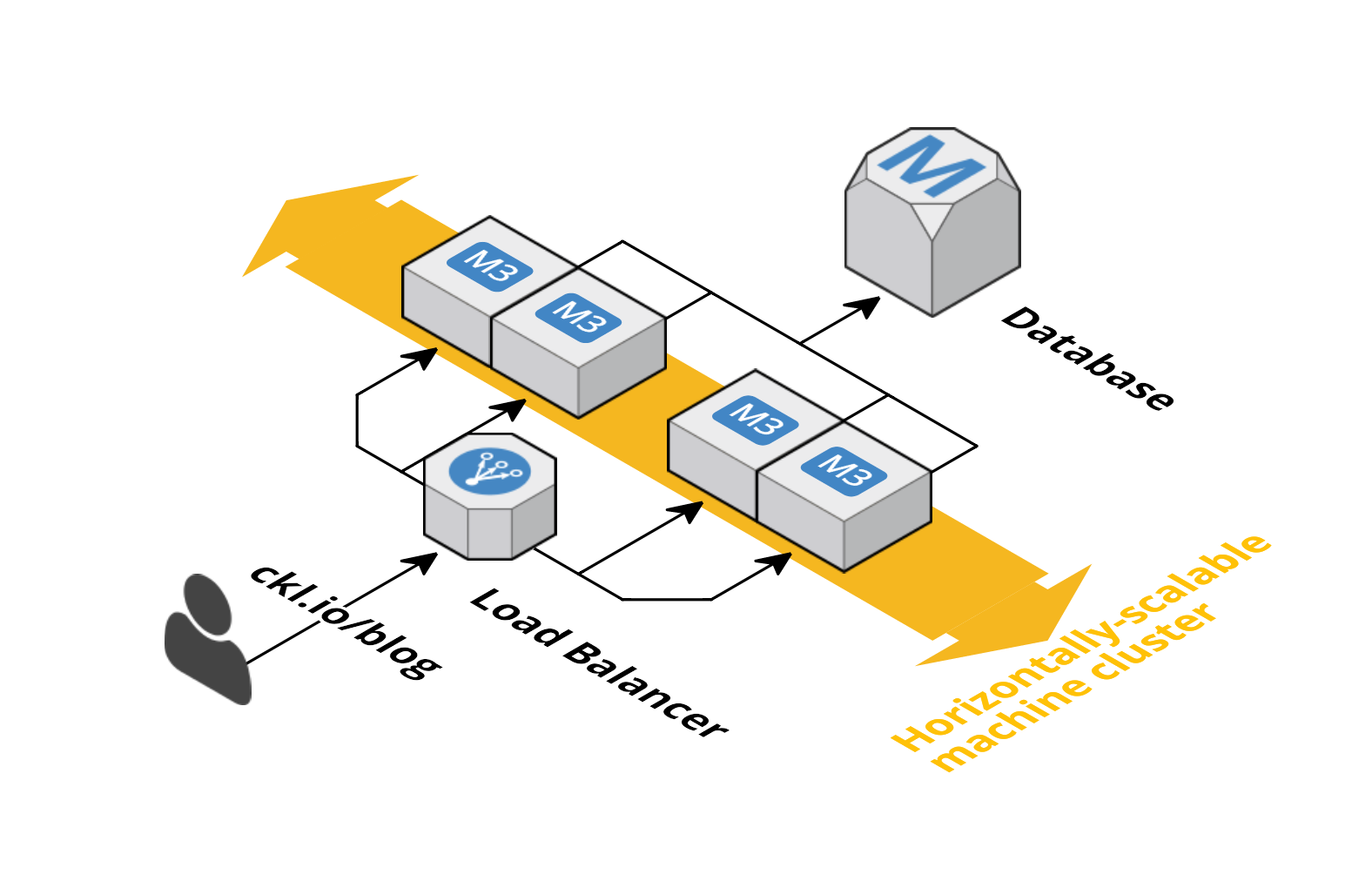
When using a load balancer, you can make sure you’re optimizing your resources’ usage and, based on its data, you can create triggers to add more machines to your cluster, or remove some when they become unnecessary.
This also adds redundancy to the system, which means that, if one machine in the cluster stops working for whatever reason, the remaining ones can seamlessly take over.
Amazon Web Services provides a great built-in service for load balancing, Elastic Load Balancing, which is simple to configure and does all the routing to the machines you put behind it.
No matter how good, no software is bulletproof. Downtimes will eventually occur, but there are ways you can minimize how they affect your end user. A good approach is to save the most frequent requested data in a separate place, which we call a cache. This way, if your cloud goes down, you can serve a cached response – which might be useful enough for the majority of the applications, since they don’t always require providing up-to-the-second-fresh data.
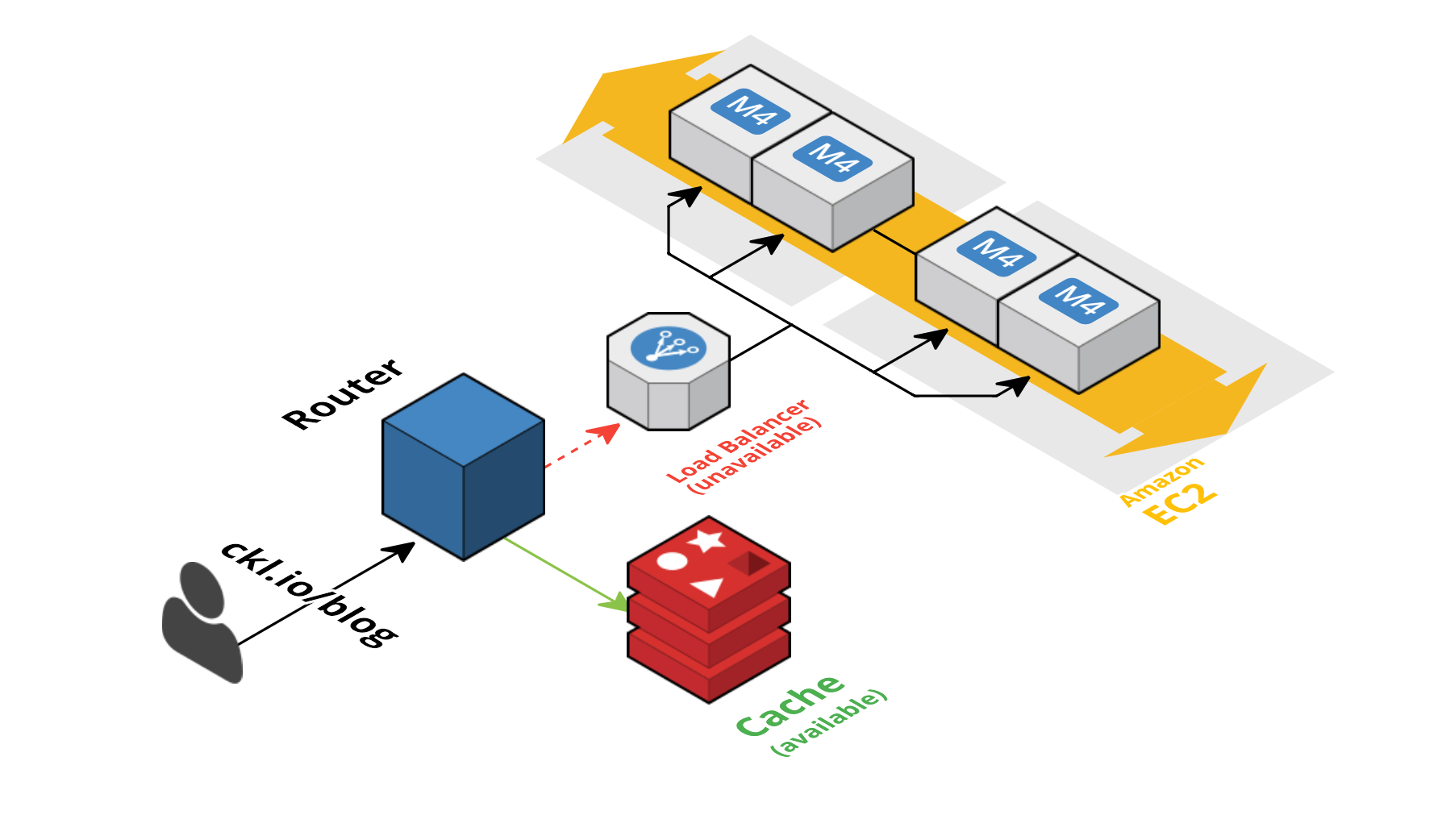
This doesn’t solve some edge cases, like a chat application, where the immediate delivery of new messages is core – but at least you’d have access to the chat history when things are down.
CloudFlare has a powerful (and free) caching tool that seamlessly caches your requests in the frequency of your choice. It also has an ‘Always Online’ feature that serves a cached version of your site if your cluster goes down.
If your application has a search engine on its core, one thing is for sure: unless you choose the right structure, your search functionality will become very slow when things scale up.
This is because most of the database technologies aren’t optimized for full-text search on large volumes, which means they’ll take more and more time to find what you’re looking for over time (especially when many users are performing searches at the same time).
In order to avoid that, there are technologies that distribute the search work into several machines and create a map of the data, like distributing books within various library sections, and having a librarian for each of the sections.
The most famous ones are Elastic and Algolia, and they will handle the search work like a breeze.
Ok, this might sound obvious – but most people take their cloud for granted. It is essential to monitor what is going on and set up alarms/alerts to take measures regarding your cloud’s structure.
When monitoring, it’s easier to identify bottlenecks and also where resources can be cut down without any damage to the system’s function. Tools like New Relic, Pingdom, Loggly, and AWS CloudWatch will make sure you’ll get alerts whenever something unusual is going on.
All in all, cloud scaling consists of making the architecture as modular, distributed and redundant as possible. As said, these were just a few very basic steps – and making scalable architectures is a whole science by itself.
When thinking about allocating resources, prices should be taken into account, since making an extremely modular architecture for a really small user base might be an overkill – so make sure you find the right timing for scaling things up.
Vertical scaling means switching existing machines to more powerful ones so they can handle more tasks, which can be a short-term solution but leads to exponentially growing expenses as you reach the bleeding edge of hardware. Horizontal scaling means adding more less-capable machines and distributing tasks among them, with prices growing linearly, and allows you to add or shut down machines without migration or downtime.
A load balancer is a machine that knows where all the other machines are and what kind of tasks they can handle, redirecting access to the least busy machine. It optimizes resource usage, enables triggers to add or remove machines from the cluster, and adds redundancy so that if one machine stops working, the remaining ones can seamlessly take over.
Saving the most frequently requested data in a cache allows you to serve a cached response if your cloud goes down, which can be useful for applications that don't require up-to-the-second-fresh data. CloudFlare offers a caching tool with an 'Always Online' feature that serves a cached version of your site if your cluster goes down.
Most database technologies aren't optimized for full-text search on large volumes, so searches take more time as data grows, especially with many simultaneous users. Technologies like Elastic and Algolia distribute the search work across several machines and create a map of the data to handle searches efficiently.
Tools like New Relic, Pingdom, Loggly, and AWS CloudWatch can send alerts whenever something unusual is happening, helping identify bottlenecks and areas where resources can be cut down without damaging the system's function.